


1. Les fondamentaux de la gestion de la mémoire par une JVM▲
Une machine virtuelle Java (une JVM) est un environnement d'exécution complexe. Ce point est d'autant plus vrai si l'on regarde les mécanismes mis en jeu pour garantir la bonne gestion de votre mémoire. Au niveau des spécifications Java SE, il est dit que l'allocation de la mémoire est de votre responsabilité, mais la libération de la mémoire est de la responsabilité de la JVM. Mais cette spécification n'impose pas d'algorithmes de ramasse‑miettes particuliers. Chaque implémentation de JVM est donc libre de réaliser cette gestion à sa manière (pour peu que la mémoire soit finalement libérée). Nous ne pourrons pas dans ce document traiter toutes les JVM existantes. Nous nous concentrerons donc principalement sur celle d'Oracle, qui est souvent considérée comme étant l'implémentation de référence. Cette JVM a un petit nom : Hotspot.
Un point relativement important est à garder en tête : ce tutoriel adresse principalement la version 6.0 du Java SE d'Oracle : effectivement, c'est encore cette version qui est la plus massivement utilisée en entreprise. Entre la version 6.0 et 7.0 de la JVM les choses seront très fortement similaires (à quelques options près sur la section I-B). Par contre, la future version 8.0 du Java SE apportera un changement important (disparition de l'espace relatif aux objets permanents, nous allons y revenir).
1-A. Les algorithmes majeurs utilisés pour mettre en œuvre un Garbage Collector (GC)▲
Assez classiquement, une JVM propose un GC générationnel : cela veut dire que votre espace de mémoire est divisé en plusieurs zones de mémoire. Chaque zone de mémoire correspond à une génération d'objet et utilise un algorithme de GC adapté à cette génération d'objets. Dans le cas de Hotspot, il y a trois générations d'objets. Ces trois générations sont :
- l'espace des jeunes objets (aussi appelé Young Space) : cet espace de mémoire est traité avec un algorithme dérivé de Stop and Copy. Cet algorithme est adapté à la gestion d'objets de faible durée de vie. Statistiquement, une très grande proportion d'instances Java produites meurt rapidement : il est donc important de plutôt favoriser les temps d'allocation. Pour ce faire, le Young Space est divisé en trois parties distinctes : l'Eden et deux Survivor Spaces ;
- l'Eden (le paradis des objets Java) est l'espace dans lequel toutes les instances Java naissent : cette zone peut être vue comme une pile ;
- les Survivor Spaces permettent la recopie des objets survivants. Effectivement, dès que l'Eden est saturé, on recopie l'ensemble des survivants dans l'un des deux Survivor Spaces. Lors de la prochaine saturation de l'Eden, tous les survivants de cette zone ainsi que du précédent Survivor Space seront recopiés dans l'autre Survivor Space et ainsi de suite.
- Après chaque recopie des survivants, l'Eden est considéré comme vide et on peut commencer à le réalimenter. On bout d'un certain nombre de recopies, un objet sera considéré comme ancien et sera alors déplacé dans le « Old Space » : effectivement recopier ad vitam æternam des instances n'est pas forcément une bonne idée (déplacer un objet en mémoire sous-entend de mettre à jour toutes les références vers cet objet).
- Le terme « stop » insiste sur le fait que durant la recopie des objets d'un espace à un autre, vos threads se devront d'être arrêtés afin de garantir l'intégrité de vos données. Notez aussi que si une instance dépasse une certaine taille, on considère alors qu'elle risque de vivre plus longtemps et on la crée alors directement dans le « Old Space ».
- L'espace des vieux objets (aussi appelé Old Space ou encore Tenured Space) : cet espace de mémoire est géré avec l'algorithme Mark and Sweep. Cet algorithme est plus adapté pour la gestion d'objets de longue durée de vie. Or un programme utilise souvent des instances de courte durée de vie et des instances de longue durée de vie : c'est pour cela que Hotspot vous propose ces deux algorithmes. Notez aussi que l'algorithme proposé cherche à compacter la mémoire, ce qui entraine encore des déplacements d'instances. Avec cet algorithme, les objets trouvent assez rapidement leur place définitive, car les objets de très longue durée de vie se retrouvent compactés en début de l'espace mémoire de la génération ancienne. Ce compactage de l'espace mémoire permet de pouvoir instancier des gros objets (tableaux…). Sans ce compactage, vous pourriez avoir beaucoup de mémoire disponible, mais très fortement fragmentée et il serait alors impossible d'avoir un espace de mémoire compact et suffisamment grand.
- Et enfin l'espace des objets permanents (aussi appelé Perm Gen, pour Permanent Generation) : un objet permanent est un objet dont on est certain qu'il ne sera pas relâché avant la fin de l'exécution de la JVM. Du coup, il devient inutile de lancer un algorithme de ramasse- miettes sur cet espace mémoire. Il serait donc dommage de les placer dans le Young Space ou le Old Space : on saturerait les espaces plus fréquemment et donc on consommerait plus de temps CPU pour l'exécution du GC. On soulage ainsi l'activité du GC. Durant l'exécution d'une JVM, la taille du Perm Gen ne peut qu'augmenter : souvent elle augmente très rapidement au démarrage de la JVM puis sa croissance ralentit très rapidement. Cela est dû à la nature des instances qui y sont stockées : pour être considérée comme permanente, une instance Java doit être préfixée des qualificateurs static et final et donc être un attribut de classe.
Je me permets de réinsister sur le fait que l'espace pour les objets permanents disparaitra prochainement avec la sortie de la version Java SE 8.0 d'Oracle.
Pour de plus amples informations sur les algorithmes cités ci-dessus, je vous renvoie vers le site Wikipedia sur lequel vous trouverez quelques compléments d'information.
Le diagramme proposé ci-dessous vous montre ces différents espaces mémoire. Les proportions de tailles des différents espaces mémoire ne sont absolument pas représentatives de la réalité. La zone de mémoire appelée Code Cache correspond à l'endroit où sont montés les codes machines de vos différentes classes.

Quand une phase de nettoyage de la mémoire (une phase de GC) se déclenche, tous les espaces ne sont pas forcément collectés (nettoyés). Une collecte mineure correspond à un nettoyage du Young Space. Il se peut que certaines instances Java passent dans le Old Space durant cette phase de collecte mineure : du coup, si le Old Space se sature, cela déclenche une phase de collecte majeure (Full GC). Le Old Space étant très souvent bien plus grand que le Young Space, mécaniquement le temps d'une collecte majeure sera plus long que celui d'une collecte mineure.
1-B. Quelques options de la JVM Hotspot▲
Il est important de comprendre que la JVM Hotspot possède des limites en termes de taille mémoire qui sont infranchissables. Ces limites sont au nombre de deux. L'espace occupé par le Young Space et le Old Space ne doit pas excéder la taille spécifiée par l'option -Xmx. De même le Perm Gen ne pourra pas excéder la taille spécifiée par l'option -XX:MaxPermSize. Si l'une de ces deux limites est atteinte, une exception de type java.lang.OutOfMemoryError sera déclenchée ce qui aura pour effet de stopper le thread ayant déclenché cette exception.
-Xmx800m : permet de fixer un heap de 800 mégaoctets pour les old et young spaces.
-XX:MaxPermSize=256m : permet de fixer un Perm de 256 mégaoctets.
Il vous est possible de contrôler, en termes de ratios, les tailles des différents espaces mémoire associés au Young Space et Old Space. Pour ce faire, la JVM propose les options qui sont présentées ci-dessous. Imaginons que la mémoire occupe, à un instant donné, une taille de 96 mégaoctets.
-XX:NewRatio=2 : indique que le Old Space (64 Mo) est deux fois plus grand que le Young Space (32 Mo).
-XX:SurvivorRation=2 : indique que l'Eden (16 Mo) est deux fois plus grand que l'un des deux Survivor Spaces (8 Mo chaque espace).
Attention : les valeurs proposées le sont à titre d'exemple et vous ne devez pas considérer que ces valeurs soient optimales, bien au contraire. Il est donc de votre responsabilité, en fonction de la manière qu'a votre application de consommer les objets, de correctement configurer ces valeurs. Si vous ne maitrisez pas ces paramétrages, je vous conseille de conserver ceux proposés par défaut par la JVM.
Il vous est possible de surveiller l'activité du garbage collector : les traces sur cette activité peuvent être produites soit sur la sortie standard de votre JVM soit vers un fichier spécifique (en fonction des options utilisées). Qui plus est, vous pouvez obtenir un rapport simplifié (par défaut), soit un rapport détaillé de l'activité du garbage collector. Voici quelques options utiles pour surveiller cette l'activité :
-verbose:gc : permet d'afficher l'activité du GC sur la sortie standard de la JVM considérée ;
-Xloggc:filename : permet de stocker des logs sur l'activité du GC dans le fichier spécifié ;
-XX:+PrintGCDetails : demande à produire un rapport détaillé (zone par zone) de l'activité du GC. Cette option fonctionne aussi bien en complément de l'option -verbose:gc qu'avec l'option -XX:+PrintGCDetails.
Enfin, notez qu'il est possible de demander à la JVM de réaliser un dump de sa mémoire en cas de crash, suite à un dépassement de mémoire disponible (java.lang.OutOfMemoryError). Pour ce faire, utilisez la première option qui suit : notez qu'ensuite, il existe un ensemble d'outils permettant d'analyser ce dump mémoire (nous y revenons dans le chapitre qui suit) :
-XX:+HeapDumpOnOutOfMemoryError : produit un dump mémoire en cas de saturation de la mémoire disponible ;
-XX:HeapDumpPath=path : permet de contrôler le répertoire dans lequel seront produits les rapports.
Pour de plus amples informations sur les autres options que supporte la JVM (il y en a beaucoup d'autres), vous pouvez consulter le document suivant.
2. Les outils pouvant être utilisés durant une campagne de tests techniques▲
Vouloir chasser les fuites mémoire ou chercher à vérifier s'il y a des fuites dans une application quelconque (application Web ou non) est un objectif louable. Néanmoins, il nous faut être en mesure de collecter certains indicateurs : taux d'occupation des différents espaces mémoire, empreinte du garbage collector… Il nous faut donc utiliser un certain nombre d'outils.
L'écosystème Java a produit un très grand nombre d'outils pouvant être utilisés pour profiler une JVM. Certains d'entre eux sont directement proposés par le Java SE (sous condition d'avoir le JDK(Java Development Kit : une distribution de Java SE intégrant les outils de développement)) et d'autres sont à télécharger sur Internet. Certains sont gratuits et d'autres sont payants. Dans ce tutoriel nous ne présenterons que des outils gratuits, même si certains autres outils payants seraient extrêmement intéressants (je pense par exemple à JProfiler).
2-A. Utilisation de la JConsole▲
En premier lieu, je voulais vous présenter la JConsole : elle est proposée de base dans le JDK. Elle se connecte à un processus Java en cours d'exécution (avec possibilité de connexion à distance). À la base, il s'agit du client universel JMX (Java Management eXtension) : elle permet donc d'accéder aux MBeans (Managed Beans) de votre JVM pour administrer cette JVM. La capture d'écran suivante montre une JConsole connectée à un serveur Tomcat (pour information, Catalina est le nom originel de Tomcat ; aujourd'hui il est associé au conteneur de servlets contenu dans Tomcat). Notez que la capture proposée correspond à l'onglet « MBeans ».

Note : vous retrouverez, dans la capture d'écran ci-dessus, l'acronyme PS : celui-ci signifie Parallel Scavenger (nettoyeur parallèle). Cet acronyme apparaît si votre JVM utilise plusieurs threads pour l'exécution du GC. Il est tout à fait possible que vous ne l'ayez pas sur votre propre console.
Notez qu'on y retrouve les informations sur les différentes zones mémoire (Code Cache, PS Perm Gen, PS Eden Space, PS Suvivor Space, PS Old Gen) ainsi que des informations sur les deux types de GC (PS MarkSweep (Full GC) et PS Scavenge (Minor GC)). Il est à noter que, même si les termes employés dans l'outil sont sensiblement différents des termes utilisés dans le diagramme présentant les différentes zones mémoire, on parle des mêmes choses : par exemple, la zone mémoire ici appelée PS Old Gen correspond à la zone de mémoire Old Space (parfois aussi appelée Tenured Space) du diagramme proposé plus haut. Cliquez sur les sections « Attributes » de chaque zone mémoire pour en obtenir de plus amples informations.
Le problème de cet affichage c'est que nous avons les valeurs instantanées, mais pas l'historique des valeurs (notez cependant l'obligation de cliquer sur le bouton « Refresh » pour réactualiser les données affichées). Pour obtenir l'historique des valeurs, préférez l'utilisation de l'onglet « Memory ». Des courbes vous seront proposées pour chaque espace mémoire. Voici un exemple d'affichage possible : notez bien que l'historique des données démarre lors de l'accrochage de la JConsole à votre processus.
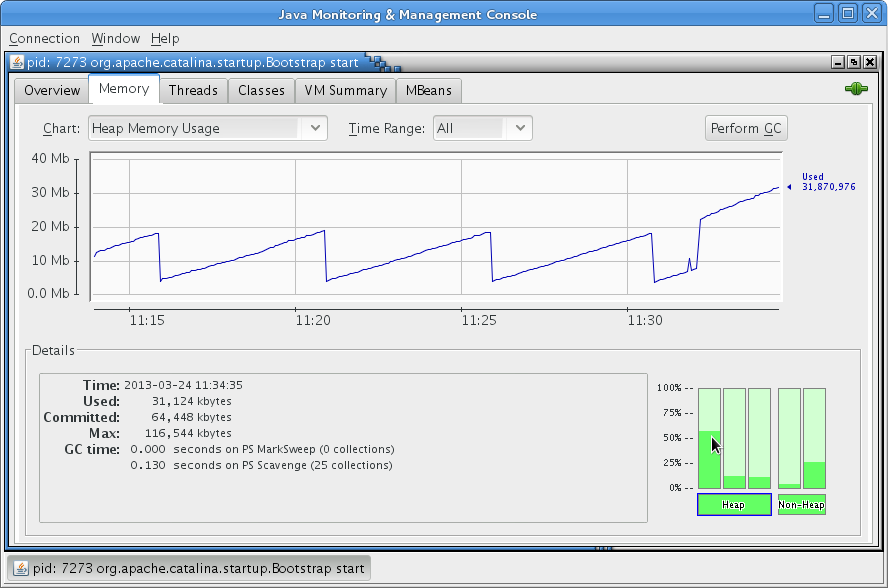
Pour changer l'espace mémoire pour lequel produire une courbe d'historique, il vous suffit de cliquer sur l'une des jauges vertes en bas à droite de la fenêtre. En laissant la souris immobile suffisamment longtemps sur une jauge, vous verrez apparaître une bulle d'information qui vous indiquera le nom de l'espace mémoire associé. Les blocs « Heap » et « Non-Heap » correspondent respectivement à la somme des blocs mémoire nettoyables par GC et à la somme des blocs de mémoire non nettoyables par GC (Perm Gen et Code cache).
Notez qu'il vous est possible de laisser tourner la JConsole très longtemps, des rééchantillonnages des valeurs acquises étant régulièrement réalisés afin de garantir que la JConsole ne tombera pas en OutOfMemoryError. Pour ma part, j'ai déjà fait tourner une JConsole pendant plus de trois semaines afin de vérifier qu'il n'y a pas de fuites de mémoire. En parallèle j'utilise l'outil JMeter pour simuler des utilisateurs. Si à la fin d'une campagne de tests sur plusieurs jours, la consommation moyenne de la mémoire est en croissance constante, alors il y a de fortes chances qu'il y ait une ou plusieurs fuites mémoire.
2-B. Visual GC : Visual Garbage Collection Monitoring Tool▲
Cet outil, aussi connu sous le nom de JvmStat, est proposé par Oracle, néanmoins il n'est pas livré dans le JDK : c'est dommage. Vous pourrez le trouver en recherchant « VisualGC » dans votre moteur de recherche favori, ou bien en activant ce lien (en espérant que l'URL ne change pas trop vite) : http://www.oracle.com/technetwork/java/jvmstat-142257.html#Download. Cet outil permet de se connecter à une JVM en cours d'exécution et de faire un état de l'activité du GC et de la consommation de la mémoire. D'une certaine manière, il est plus précis que la JConsole (notamment, il affiche séparément la consommation de chaque Survivor Space) par contre l'outil n'historise pas les résultats.
Du coup, il y a au moins un point sur lequel il est très pratique : si, lors d'un GC mineur, il y a trop d'instances survivantes par rapport à l'espace disponible dans l'un des deux Survivor Spaces, alors le surplus d'objets sera directement renvoyé dans le Old Space. Néanmoins, les objets déplacés avaient peut-être une espérance de vie courte : cela augmente donc la fréquence de déclenchement des GC majeurs. Dans ce cas, il est peut-être nécessaire de modifier le paramètre -XX:SurvivorRatio pour mécaniquement obtenir une augmentation des performances. Visual GC est donc très pratique pour vérifier ce genre de scénario.
Visual GC se lance en mode ligne de commande. Il accepte en paramètre le PID (Process Identifier) de la JVM à profiler. Vous pouvez trouver ce PID via le gestionnaire des tâches de votre système d'exploitation. Néanmoins, il est aussi possible de connaitre les PID de tous les processus Java en cours d'exécution. Pour ce faire, utilisez la commande jps. Cette commande est fournie par le JDK.
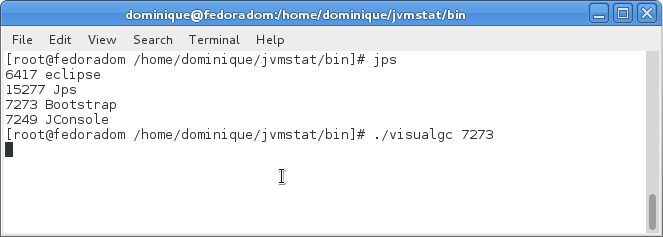
Une fois VisualGC lancé, vous obtenez deux (ou trois, précédemment) fenêtres qui affichent des informations sur votre JVM. Notez que l'outil cherche, plus ou moins, à respecter les proportions de tailles entre les différents espaces mémoire.
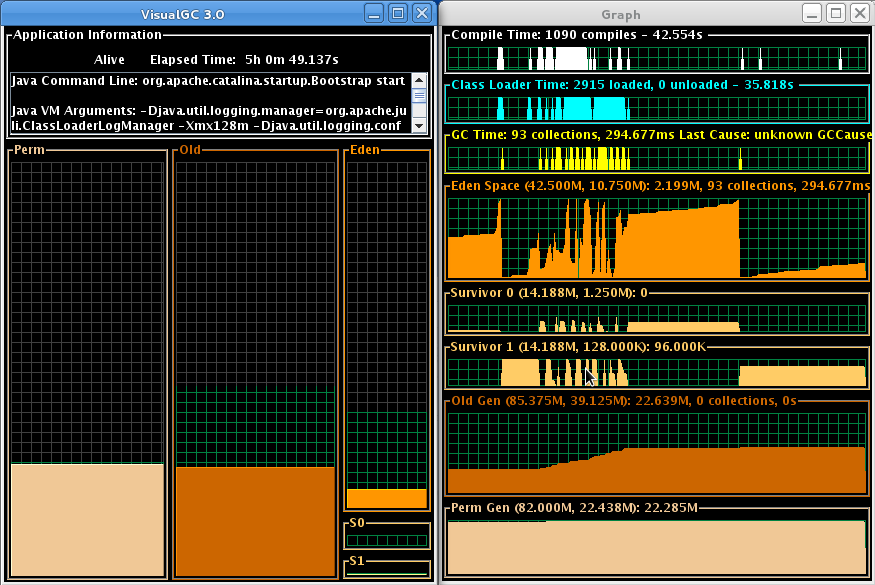
Si vous regardez bien la fenêtre de gauche, chaque espace mémoire de la JVM vous est présenté (excepté la zone mémoire relative au code : Code Cache). Un jeu de trois couleurs est utilisé. Le quadrillage gris montre l'espace total que votre processus Java pourrait atteindre (dans les limites de -Xmx et -XX:MaxPermSize). Le quadrillage vert montre l'espace de mémoire actuellement engagé par votre processus pour la zone de mémoire considérée. Le bloc orange montre la mémoire utilisée par la JVM dans l'espace alloué : noté que quand la zone orange rattrape le quadrillage vert, alors une nouvelle collecte de mémoire est lancée. Notez aussi les bascules d'utilisation entre les deux « Survivor Spaces ».
2-C. GCViewer▲
GCViewer est autre outil que l'on peut trouver sur Internet. Il est complémentaire aux deux précédents outils et fonctionne légèrement différemment. Effectivement, GCViewer travaille sur un rapport d'activité de GC et non sur un processus en cours d'exécution. Il est donc nécessaire d'éditer les scripts de lancement de votre serveur (ou tout autre processus Java que vous souhaiteriez analyser). Je vous propose l'ajout des deux options suivantes : -Xloggc:filename et -XX:+PrintGCDetails. Faites bien attention à la localisation du fichier que vous allez produire.
Il est important de noter que l'utilisation de ces deux options ne coute pas beaucoup plus cher en termes de temps d'exécution. Vous pouvez donc générer des rapports d'activité de votre JVM même sur un serveur en production.
Une fois que vous avez produit votre rapport d'activité du GC pour votre JVM vous pouvez lancer GCViewer est ouvrir votre rapport. Pour ce faire lancer la commande suivante dans une console : java -jar gcvierwer-1.29.jar (attention, le numéro de version peut varier). Ouvrez le fichier le log à partir du menu « File ». Un rapport visuel apparaît avec plusieurs courbes (de différentes couleurs) : vous avez le choix d'afficher ou non chacune de ces courbes. Notez aussi que certains indicateurs ont été calculés : ils sont présentés en bas à droite de la fenêtre.
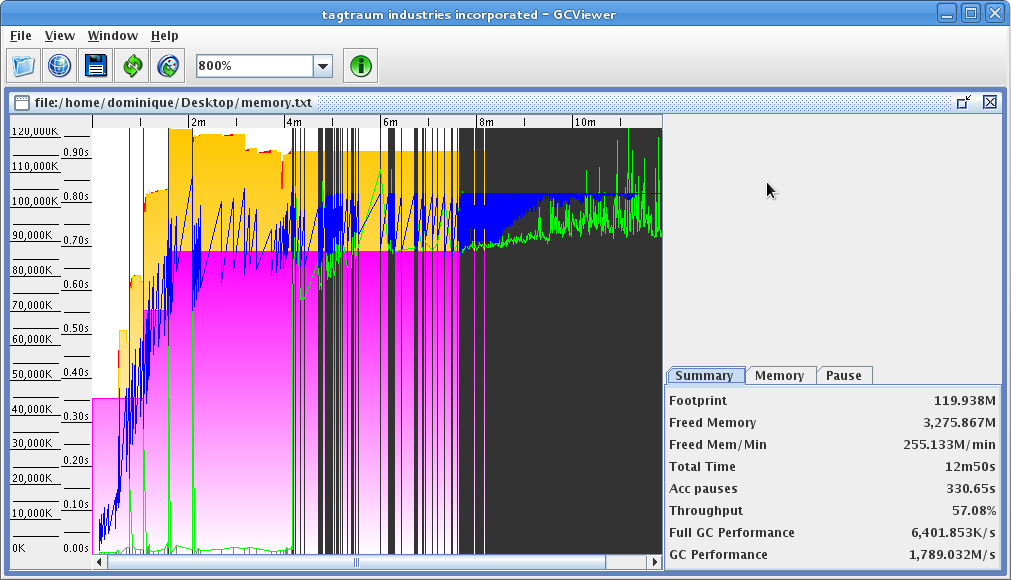
L'exemple proposé est typique de ce qu'il ne faut pas qu'il vous arrive. L'application en test consomme de plus en plus d'objets (imaginons une fuite de mémoire). Or la mémoire disponible est trop juste. Ce qu'il faut regarder, c'est la courbe bleue. Elle correspond à la mémoire consommée : on voit bien qu'elle tend vers une limite. Au démarrage, des phases de collectes mémoire ont lieu et la mémoire consommée retombe. Mais vers le dernier quart du diagramme, la mémoire ne redescend quasiment plus : c'est normal, car tous les objets sont référencés en mémoire et sont donc considérés comme utiles par la JVM. Du coup, les phases de collectes majeures sont deux plus en plus rapprochées. Un trait noir correspond à un GC majeur : notez, sur la fin le rapprochement des barres. La JVM passe donc un maximum de temps à nettoyer la mémoire. Il faut aussi remarquer que les GC majeurs durent à peu près une seconde. En gros, c'est la catastrophe absolue.
Parmi la liste des indicateurs proposés à droite, j'attire votre attention sur le Throughput (le débit) : il est de 57,08 %. Cet indicateur correspond au temps total passé dans vos threads et hors GC par rapport à la durée d'exécution de votre processus. Ici, on passe donc autant de temps dans le GC que dans le programme : ce n'est vraiment pas bon. Un bon débit devrait être de plus de 95 %. Un très bon débit serait proche de 99 % (seulement 1 % de temps consommé par le GC).
La situation ici observée est très proche de ce qui se passe sur un Tomcat hébergeant des applications produisant des fuites mémoire. Au début de son exécution, tout va bien. Puis, progressivement, la mémoire utilisée se rapproche de la limite utilisable. Les GC majeurs deviennent des plus en plus proches et du coup les temps de réponse du serveur se dégradent de plus en plus, jusqu'à ne même plus arriver à avoir de retour de Tomcat étant donné qu'il passe son temps à faire des GC. Vous allez alors le redémarrer jusqu'à la prochaine fois où la mémoire sera saturée. Il nous faut donc d'autres outils pour trouver les objets qui ne sont pas relâchés de la mémoire (nous y reviendrons plus loin).
2-D. JMeter et les tests de montée en charge▲
Le mieux est de se rendre compte des problèmes présentés ci-dessus avant de passer l'application en production. Pour ce faire, il vous faut bâtir des batteries de tests de montée en charge (voire des tests d'endurance). JMeter, un outil proposé par la fondation Apache, peut vous permettre de réaliser ces batteries de tests.
JMeter peut être utilisé pour enregistrer un scénario de navigation sur votre serveur Tomcat (ou autre). Pour ce faire, il vous faut configurer JMeter comme étant un proxy HTTP au sein de votre navigateur Web. Ainsi, quand vous allez produire des requêtes HTTP via votre navigateur, JMeter va les réceptionner et les mémoriser. Il va aussi les rediriger sur votre serveur et du coup il recevra les réponses HTTP qu'il mémorisera aussi avant de les retourner au navigateur. Une fois votre scénario totalement enregistré, vous pouvez fermer le navigateur. Il vous est maintenant possible de rejouer votre scénario autant de fois que vous le souhaitez et en parallèle, histoire de simuler plusieurs utilisateurs.
Du coup, le serveur va monter en charge et traiter un grand nombre de requêtes. Son GC va certainement lui aussi commencer à travailler. Si en même temps, vous avez connecté la JConsole sur votre serveur et si vous produisez des logs sur l'activité du GC, il vous sera alors possible de connaitre le comportement de votre serveur. Un conseil : déterminez si votre Throughput est bon ou pas.
Vous pouvez télécharger JMeter sur le serveur Apache à l'adresse suivante : http://jmeter.apache.org.
2-E. Java Visual VM▲
Nous partons maintenant du principe que nous avons effectivement un problème de fuites mémoire. La question est donc de savoir comment déterminer quelles sont les instances qui ne sont pas relâchées et par conséquent avoir des pistes sur les portions de code à corriger. Java Visual VM, un autre outil du JDK peut vous permettre de trouver ces informations.
En fait, Java Visual VM est un sous-ensemble de l'IDE NetBeans (il s'agit des plugins de profilage) dont on a permis l'exécution en standalone. Du coup, la coquille Java VisualVM permet d'y installer des plugins complémentaires. Par exemple, il existe une intégration de VisualGC dans Java VisualVM. Cela peut être réalisé directement en ligne. Je vous conseille de tester cette possibilité.
Java Visual VM est un profileur de code Java : il se connecte sur un processus Java en cours d'exécution de manière très similaire à la JConsole. Pour ce faire, lancer la commande jvisualvm dans votre console. Une fois connectée, la console vous propose différents outils (par le biais de différents onglets). Le premier outil que je vous propose est disponible à partir de l'onglet « Profiler ». Deux types de profilage peuvent être effectués : vous pouvez choisir une campagne de profilage de type Memory. Un tableau (réactualisé périodiquement) vous propose une liste de classes ordonnées par tailles utilisées pour chaque type. Notez que vous pouvez filtrer les classes présentées par le biais de l'outil « Class Name filter » présent en bas de la fenêtre. Vous pourrez ainsi vérifier la cohérence des volumétries d'instances constatées.

Un autre outil est très pratique : il est accessible à partir de l'onglet « Monitor ». Cet onglet affiche des informations très proches de celles proposées par la JConsole. Notez néanmoins la présence du bouton « Heap Dump » : il produira un fichier contenant un dump de l'ensemble des objets actuellement en mémoire.
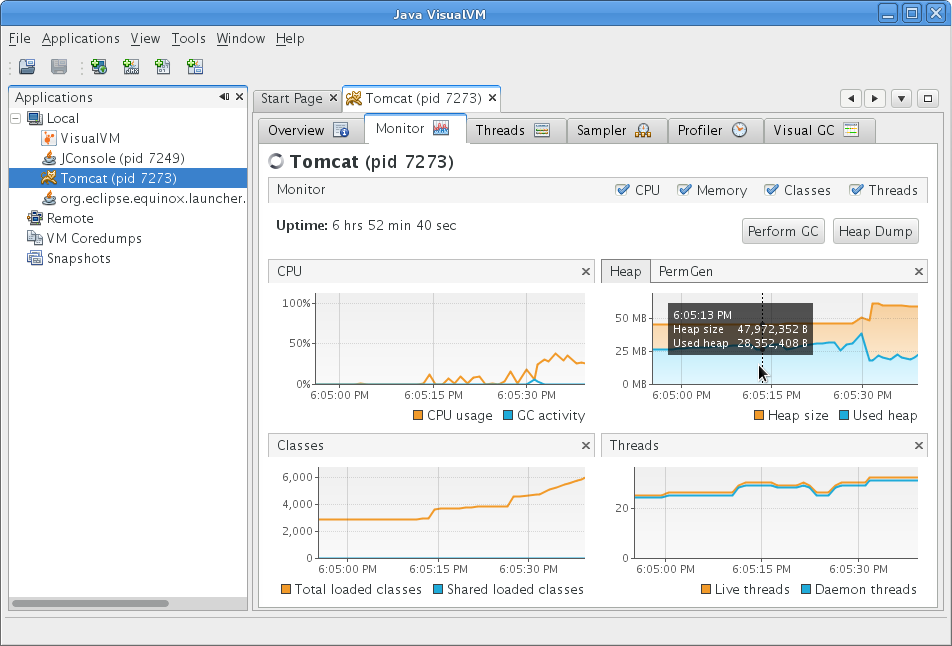
Une fois le fichier de dump produit, vous pouvez l'enregistrer sur disque (bouton droit de la souris sur le dump) et vous pourrez le consulter au travers de différents types de rapports. La capture d'écran ci-dessous présente le rapport de type « Classes ».
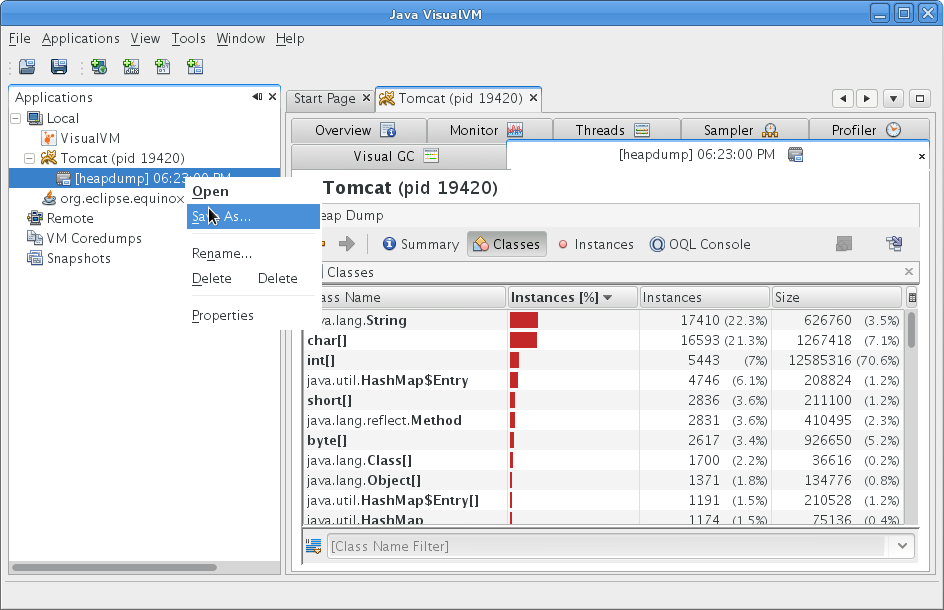
2-F. Memory Analyzer Tool▲
Pour clore ce chapitre sur les outils standard de profilage d'application Java, je ne pouvais pas passer à côté de celui qui m'a sauvé x fois la vie : Memory Analizer Tool (MAT pour les intimes). Cet outil est un plugin pour l'IDE Eclipse. Pour l'installer, je vous conseille de l'installer en ligne à partir de l'IDE Eclipse : cliquez sur l'élément de menu « Help », puis sélectionnez « Install new software… ». Le contenu du dépôt de plugins officiel devrait se présenter à vous : sélectionnez-y l'outil « Memory Analyzer ». Un redémarrage de l'IDE sera nécessaire. Pour vérifier la bonne installation du plugin, sélectionnez l'élément de menu « About Eclipse » dans le menu « Help ». Une boîte de dialogue apparaît : en cliquant sur le bouton « Installation Details » vous pourrez vérifier la présence de MAT. Notez aussi que vous pouvez télécharger une version de MAT en « standalone » : pour ce faire, activez le lien http://www.eclipse.org/mat/downloads.php.
Cet outil travaille sur un fichier de dump mémoire d'une JVM. Je vous propose trois solutions pour obtenir un fichier de dump mémoire d'une JVM (deux d'entre elles ont déjà été vues) :
- utiliser l'option -XX:+HeapDumpOnOutOfMemoryError pour le générer en cas de crash de votre application en OutOfMemoryError ;
- utiliser l'outil JVisualVM pour produire le fichier ;
- utiliser, au travers d'un shell, la commande jmap proposée par le JDK pour demander à la JVM identifiée par son PID de produire le rapport.
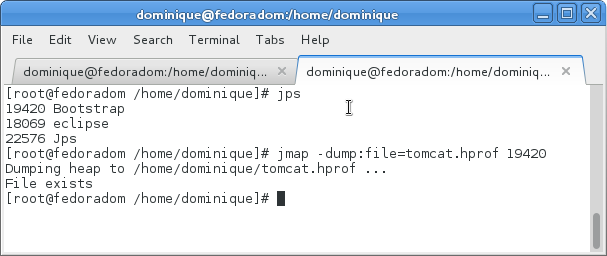
Ensuite, démarrer votre atelier Eclipse. Bien qu'une perspective Eclipse soit dédiée à l'exploitation de MAT, il vous est possible de simplement cliquer sur un fichier de rapport (il faut qu'il soit présent dans le projet Eclipse considéré et il faut que le fichier ait l'extension .hprof). Une fois l'analyse du fichier lancée, une première boîte de dialogue vous demande quel type d'analyse vous souhaitez faire : si vous chassez les fuites mémoire, demandez un rapport de type « Leak Suspects Report ».

Ensuite l'outil le plus important (du moins, à mon sens) est le « Dominator Tree ». Il présente les classes Java retenant le plus d'octets (directement et indirectement) en mémoire. Voici un exemple d'affichage de type « Dominator Tree » : pour l'obtenir, veuillez cliquer sur l'icône juste au-dessus du pointeur de la souris de la capture d'écran.
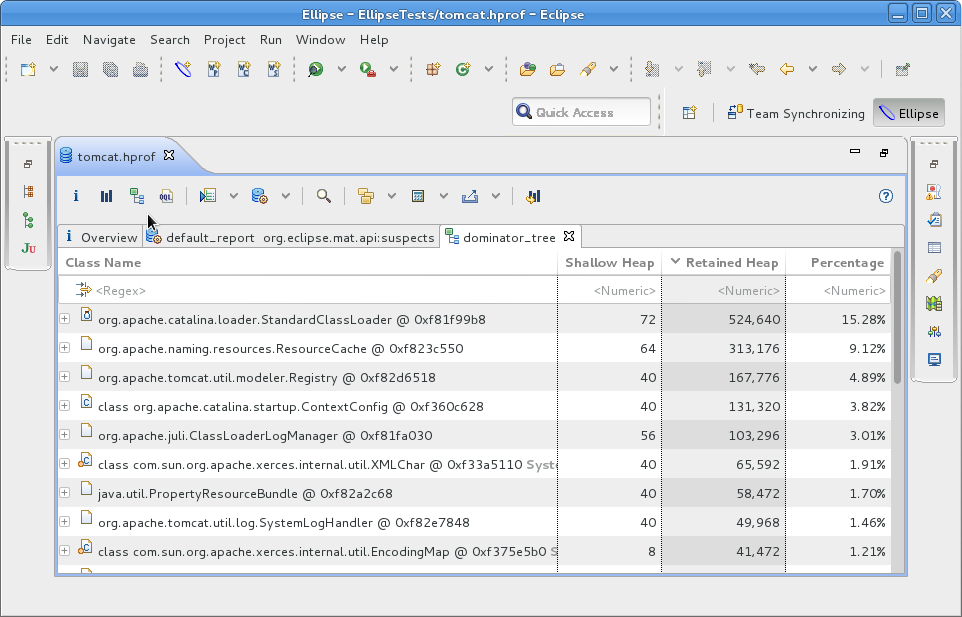
Quelques explications s'imposent : deux notions de tailles sont présentées pour chaque classe. La taille « Peu profonde » (Shallow Heap en anglais) : elle correspond à la taille consommée par les instances, sans considérer les tailles des sous-zones pointées (correspondant aux attributs de types objets : dans ce cas, seules les tailles des pointeurs seront considérées et pas les tailles des zones pointées). La taille « Retenue » (Retained Heap) qui correspond à l'ensemble des octets retenus (directement ou indirectement, au travers des zones pointées) par vos objets. Bien entendu, la taille « Retenue » et plus grande que la taille « Peu profonde ». Les classes étant triées par taille décroissante, cela vous permet de facilement localiser les grosses fuites de mémoire.
Pour comprendre comment sont structurés les octets en profondeur, il vous suffit de déployer l'arborescence de la vue « Dominator Tree ». Il existe pleins d'autres possibilités associées à MAT : je vous les laisserai découvrir par vous-même.
3. Les outils spécifiques au Framework Ellipse▲
L'objectif de ce dernier chapitre est de vous présenter les compléments d'outils que le Framework Ellipse met à votre disposition pour surveiller la consommation de la mémoire au sein du serveur. Effectivement, bien que les outils présentés précédemment soient très puissants, ils nécessitent, pour certains d'entre eux, d'être connectés à la JVM. Si votre serveur Tomcat (ou autre) est hébergé à l'extérieur, il devient plus compliqué d'obtenir certaines des informations présentées dans ce tutoriel. Pour répondre à cette difficulté, Ellipse Framework met à votre disposition un module de traces et de profilages qui peut être interrogé par HTTP avec un simple navigateur.
3-A. Configuration du module de traces▲
Pour activer le module de traces au sein de votre application, il est nécessaire de configurer le fichier WEB-INF/web.xml. Notez que vous pouvez, bien entendu, changer certaines valeurs : URL de la page de traces, login, password…
<?xml version="1.0" encoding="UTF-8"?>
<web-app version="2.4" xmlns="http://java.sun.com/xml/ns/j2ee"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://java.sun.com/xml/ns/j2ee
http://java.sun.com/xml/ns/j2ee/web-app_2_4.xsd">
<display-name>Application name</display-name>
<description>Application name</description>
<!-- Activation du module de traces -->
<context-param>
<param-name>TRACE_ENABLED</param-name>
<param-value>true</param-value>
</context-param>
<!-- Souhaitez-vous accéder aux traces à distance ? -->
<context-param>
<param-name>TRACE_LOCALHOST_ONLY</param-name>
<param-value>false</param-value>
</context-param>
<!-- Terminaison de l'URL d'accès au module de traces -->
<context-param>
<param-name>TRACE_URL</param-name>
<param-value>MyTrace.wp</param-value>
</context-param>
<!-- Nombre maximal de requêtes HTTP mémorisées -->
<context-param>
<param-name>TRACE_MAX_COUNT</param-name>
<param-value>1000</param-value>
</context-param>
<!-- Si présent, ce paramètre définit un couple login/password
pour accéder au module de traces
-->
<context-param>
<param-name>TRACE_IDENTITY</param-name>
<param-value>mylogin/mypassword</param-value>
</context-param>
<servlet>
<servlet-name>EllipseServlet</servlet-name>
<servlet-class>corelib.services.web.webapplications.ControllerServlet</servlet-class>
<load-on-startup>1</load-on-startup>
</servlet>
<servlet-mapping>
<servlet-name>EllipseServlet</servlet-name>
<url-pattern>*.wp</url-pattern>
</servlet-mapping>
<!-- Suite de la configuration de l'application -->
</web-app>L'utilisation de l'authentification pour l'accès aux traces sur un serveur de production est très fortement recommandée, sans quoi des informations importantes pourraient être facilement accessibles au travers des différentes traces. Ignorer ce point pourrait compromettre très fortement la sécurité de votre serveur.
Il est à noter que ce module de traces peut être installé dans n'importe quel WAR (Web ARchive), même si vous utilisez un autre framework Web pour la couche de présentation (Struts, Struts 2, JSF, ou autre…). Dans ce cas, n'oubliez pas de copier le JAR du Framework Ellipse dans le répertoire WEB-INF/lib de votre WAR.
3-B. Utilisation du module de traces▲
Pour accéder au module de traces, composer l'URL requise dans votre navigateur (attention, elle dépend des informations stockées dans le fichier de configuration présenté ci-dessus). Si une authentification est demandée, saisissez correctement votre identifiant de connexion et votre mot de passe. L'écran suivant doit ensuite apparaître dans votre navigateur.
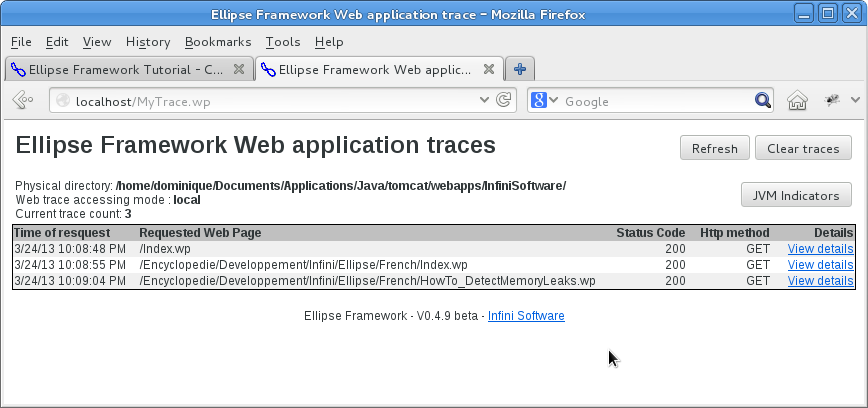
Des traces relatives à la navigation sur votre application seront, bien entendu, présentes si quelqu'un utilise un navigateur pour explorer votre application. Vous pouvez cliquer sur chaque trace pour obtenir plus d'informations sur la requête associée. Attention, seules les URL mappées à la servlet du Framework Ellipse seront considérées dans ce rapport. Vous noterez aussi le bouton « JVM Indicators ». Il permet de passer à l'écran qui nous intéresse le plus relativement à ce document : un affichage de mesure sur la consommation de la mémoire et l'activité du GC.

Comme vous pouvez le voir, trois parties sont présentées. Premièrement, des indicateurs sur l'activité du GC vous sont proposés : temps des différents GC et surtout un calcul du Throughput vous est proposé. Notez aussi le temps depuis lequel le serveur tourne (indicateur Uptime).
La seconde zone correspond à la zone de tracé des courbes en couleur : vous pouvez y suivre l'évolution de la consommation de la mémoire (Young Space + Old Space). Vous y verrez se succéder les différents GC. Notez que la fréquence de collecte de mesures est configurable. Attention : une fréquence d'échantillonnage trop rapide (1 seconde dans la capture d'écran ci-dessus) peut, dans la durée, ralentir votre navigateur. Optez plutôt pour une fréquence de l'ordre de la minute (saisir 60, secondes, dans la zone de saisie associée). Les quatre courbes correspondent à :
- Init : la taille initiale de la JVM (spécifiée via l'option -Xms de la JVM) ;
- Maximum : la taille maximale que la JVM pourrait atteindre (cette valeur est spécifiée via l'option -Xmx de la JVM) ;
- Committed : cette courbe correspond à la quantité de mémoire engagée par la JVM à un instant donné. Cette mémoire a été réservée auprès du système d'exploitation et elle est utilisée par l'allocateur mémoire de Java et ses GC pour gérer vos objets. Elle n'est pas constante et en fonction des besoins de la JVM cette quantité de mémoire peut grossir ou se réduire ;
- Used : correspond à la mémoire consommée par vos objets Java. À un instant donné, cette quantité de mémoire est forcément inférieure à la quantité de mémoire engagée auprès de l'OS (courbe Committed).On voit bien, grâce à cette courbe, les instants durant lesquels les GC ont déclenchés.
La troisième affiche l'état, en instantané, des zones mémoire non gérées par un GC (Perm Gen et Code Cache).
Dernière remarque importante : bien que présentées dans les traces d'une application Web, les valeurs affichées dans cette page sont communes à toutes les applications déployées dans ce serveur d'applications. Cela est tout à fait normal, ce sont des informations propres à la JVM (et non au WAR).
4. Conclusion▲
Voilà qui clôt ce tutoriel. J'espère que celui-ci vous aura permis de mieux comprendre la gestion de la mémoire en Java ainsi que le fonctionnement du Garbage Collector. J'espère aussi qu'il vous aura donné l'envie d'aller plus loin dans la manipulation des outils présentés : bien utilisés, ils vous permettront de produire des applications robustes et stables. J'espère aussi que le module de traces du Framework Ellipse vous apportera entière satisfaction.
5. Remerciements▲
Merci à Mickeal Baron d'avoir cru en Ellipse Framework, et nous avoir permis de publier nos tutoriels sur « Developpez.com ».
Merci à Olivier Pitton, Stessy Delcroix, Damien Rieu, Yann Caron et Thierry Leriche-Dessirier pour leur relecture technique.
Merci à Claude Leloup pour sa relecture orthographique.
Et enfin, merci à tous ceux qui font confiance à Ellipse Framework.
L'équipe « Ellipse Framework ».